
5 Exciting RAG Projects Beginners Can Try in 2025
In the fast-growing world of artificial intelligence, one challenge has consistently slowed down the adoption of large language models (LLMs): their reliability. Two primary limitations keep emerging in discussions: hallucinations and outdated knowledge.
If you’re curious about new AI methods shaping training, check out WTF is GRPO: The AI Training Method Changing.
Hallucinations refer to when models generate information that is false but delivered with confidence. Outdated knowledge arises because these systems are trained on data up to a certain cutoff date, meaning they cannot access new or real-time information. These two hurdles raised major doubts about depending on LLMs in sensitive or professional environments.
To address these concerns, Retrieval-Augmented Generation (RAG) has become a powerful alternative. RAG blends the strengths of information retrieval with generative models to deliver more factual, up-to-date, and context-aware responses. Today, RAG is no longer experimental; it is widely adopted across industries, from education and healthcare to finance and law.
Still, most newcomers limit themselves to one standard setup: connecting a vector database to text documents and performing retrieval. While this works for simple needs, it restricts creativity and real understanding.
This news report focuses on a broader, more engaging approach. Rather than narrowing down on one structure, we highlight five unique, practical, and enjoyable projects that beginners can explore in 2025. These projects showcase how adaptable RAG can be and inspire aspiring developers to design their own custom applications.
1. Building a RAG Application Using Open-Source Models
Link: Watch tutorial here
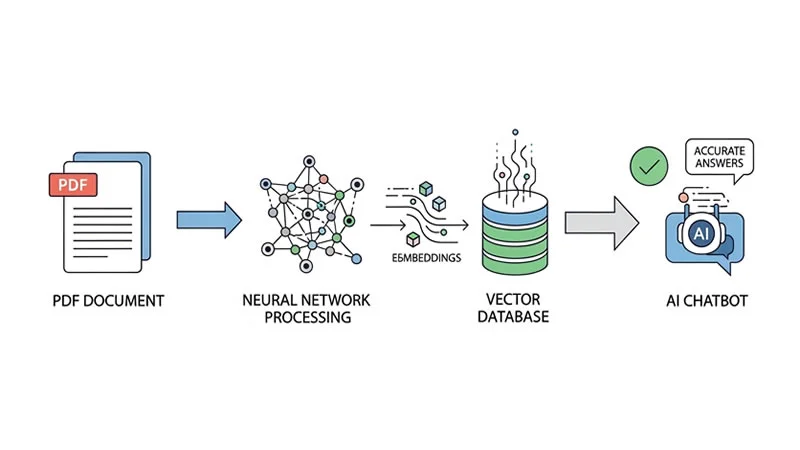
Starting with the fundamentals, beginners should first construct a basic retrieval-augmented generation system using accessible tools. In this project, you will learn to create a question-answer bot capable of answering queries from any PDF file. The setup uses Llama2, an open-source large language model, which can be executed locally through Ollama without relying on costly APIs.
The process involves splitting PDF documents using PyPDF from LangChain, generating embeddings, and storing them in lightweight vector memory such as DocArray. Afterward, a retrieval chain is set up in LangChain, enabling the system to locate the most relevant passages and produce accurate answers.
Throughout the tutorial, beginners gain experience with local models, vector stores, and retrieval pipelines. By the end, you will have a functional system capable of answering context-specific queries like “What is the course duration?” based on the PDF’s content.
2. Multimodal RAG: Working with Text, Images, and Tables
Link: Watch tutorial here
Once text-only RAG is understood, it’s time to advance toward multimodal systems. Unlike earlier setups that process only text, multimodal RAG handles mixed content documents containing text, tables, and images. In this project, popular educator Alejandro AO demonstrates how to use LangChain together with the Unstructured library to analyze hybrid PDFs.
The workflow begins with extracting structured and unstructured content, converting it into embeddings, and saving them inside a vector database. The key difference is the use of multimodal LLMs such as GPT-4 with vision, which can interpret graphs, charts, and images alongside regular text.
A retrieval chain is then built to unify all formats, allowing you to ask questions like: “Summarize the graph on page 7 and compare it with the table on page 9.” This capability mirrors how real analysts combine multiple data types into one coherent answer.
3. On-Device RAG with ObjectBox and LangChain
Link: Watch tutorial here
Privacy, independence, and cost-efficiency are strong reasons why many developers seek local-only solutions. This project demonstrates how to construct a completely offline RAG system that functions entirely on your device. The highlight is ObjectBox, a compact yet powerful vector database built for local deployment.
Using LangChain, learners will set up retrieval and response generation pipelines that run without any external services. The result is a fast, secure, and private AI assistant that analyzes your personal documents directly on your computer. This type of solution is especially attractive for professionals working with confidential data lawyers, doctors, researchers, or businesses concerned about security leaks. Moreover, it reduces expenses by eliminating recurring API costs.
4. Real-Time RAG with Knowledge Graphs (Neo4j + LangChain)
Link: Watch tutorial here
While most RAG setups rely on flat documents, real-time scenarios often require deeper context and relationships. That’s where knowledge graphs come in. This project introduces Neo4j, a popular graph database, to store interconnected nodes and edges representing structured knowledge.
Working in an interactive notebook, you’ll connect Neo4j with LangChain to build a retrieval pipeline that understands complex relationships. For example, instead of just retrieving a single chunk of text, the system can answer: “Which author collaborated with Dr. Smith, and what was their last joint publication?” The tutorial covers graph queries using Cypher, visualization of results, and integration with an LLM to deliver context-rich responses.
For readers preferring detailed documentation, an in-depth article titled Building a Graph RAG System: A Step-by-Step Approach is also available, guiding you through the entire setup process.
5. Implementing Agentic RAG with Llama-Index
Link: Watch playlist here
The final project takes RAG one step further by incorporating reasoning loops and interactive tools, creating what is known as Agentic RAG. Instead of merely retrieving data, the system is equipped with multiple skills and decision-making capabilities.
This tutorial series by Prince Krampah divides the process into four stages:
- Router Query Engine: Configure Llama-Index to send queries to the correct source, whether a vector store or summary index.
- Function Calling: Add external tools such as calculators, web APIs, or search engines for real-time updates.
- Multi-Step Reasoning: Teach the model to break complicated queries into sequential tasks, such as “summarize, then analyze, then compare.”
- Scaling Across Documents: Allow the system to handle multiple documents simultaneously by distributing tasks among smaller agents.
By the end, learners have a versatile AI assistant that not only retrieves facts but also reasons step by step, solves multi-document problems, and integrates with external services. This marks the beginning of more autonomous, self-directed AI workflows.

Wrapping Up
These five projects demonstrate that Retrieval-Augmented Generation is not confined to a single architecture. Beginners in 2025 have a wide range of exciting opportunities, from running offline document Q&A bots to advanced graph-based systems and agentic reasoning pipelines.
The best advice for newcomers is simple: don’t chase perfection on your first try. Choose one project, experiment, and gradually mix different approaches. Each pattern you explore expands your understanding of how AI systems think, retrieve, and adapt. The future of AI lies not only in smarter retrieval but also in enabling reasoning, context awareness, and interactive problem-solving.
So, whether you are an aspiring engineer, a student, or a hobbyist, RAG offers endless creative potential. Now is the perfect time to start experimenting and bring your innovative ideas to life.